






































The Jira team builds integrations. A lot of integrations. Over the years this has meant building a number of greenfield REST APIs for both internal and external consumption. In the past 12 months, we have pivoted our thinking away from “pull in data from external vendors” to “have external vendors push data to us”. This, in turn, has seen an increase in the number of APIs we are designing and building.
Historically, our API design has been largely implementation-driven. Recently though, we have moved to spec-first API design and have seen some great benefits including reduced development times, tighter feedback loops, and better API design overall.
Could the spec-first approach work equally well for your project? Read on and find out.
This calls for a case study
To set the scene, let’s take a look at a recent project to provide feature flag integration in Jira. This project involved building a new API that external vendors could use to associate feature flags with Jira issues. This information would then be surfaced in the Jira issue view.
This project had a few interesting constraints on it:
- A tight deadline – From go-to-woah we had around eight weeks; hands-on-keyboards was closer to six weeks.
- External customers – We had three external launch partners who were looking to launch with us; they needed to build their side of the integration in the same timeframe, including consuming our new API (which didn’t exist yet).
- Unknown unknowns – We use feature flags quite heavily when developing Atlassian tools, but we have been using a single vendor and have limited experience with the models used by other feature flag vendors. In this project we needed to ensure that the domain model and API we came up with was flexible enough to cater for all feature flag vendors.
These constraints led us to one overarching driver: we needed to move quickly, and iterate on our API fast as we received feedback from our external customers.
The good(ish) old days: implementation-first API design
Historically, we’ve designed and built APIs in an implementation-first style. We might start with some initial fleshing out in Confluence to get the high-level design nailed down, but the real detailed API design happened at implementation time.
Doing API design this way has a couple of nice properties. The end result of the process is a working API implementation – there’s very little double handling going on. Plus, you can evolve the API as you encounter edge cases during unit and integration testing.
Some people would also argue that it has the benefit of keeping your API spec in sync with your implementation. The downside is that it also makes it too easy to introduce unintentional breaking changes to your API during maintenance, unless you have strict discipline or spec diffing/pact testing in place to detect it.
As with anything, however, there are a number of drawbacks to the implementation-first approach:
- Slow feedback loops – Your feedback loop from “start design” to “get feedback” is measured in days or weeks. Even if you adopt a multi-phased implementation approach where you leave rigorous testing until after the initial API design is approved, chances are you’re still going to be implementing a bunch of code before you can get anything up for review. If you need to get feedback from external customers this feedback loop is further extended with deployment cycles etc.
- Context is spread across multiple places – When you open a pull request, there is no easy way to separate out the API design from the implementation details, and reviewers need to keep the overall API shape in their head as they review multiple source files.
- Low-value review feedback – Related to #2, review feedback tends to end up being less about the API design and more about implementation details (“I think this should be moved to a separate class,” “Could we introduce some composition here to improve re-use,” etc.). While this is great for the implementation quality, it distracts from the goal of getting a solid API design.
- Frameworks leak into the design – This is my pet peeve. I often see framework concerns leaking into API design because it makes implementation easier, rather than because it makes the resulting API better. I object to having my frameworks dictate how my API behaves. How many times have you seen comments like “I did it this way because otherwise, I would need a custom Jackson de-serializer“?
- Your API spec is limited by the available tooling – Many Swagger generators don’t have full spec coverage and it can be painful to coerce them into generating the spec you want. We have had a lot of trouble in Java-land trying to get rid of readOnly flags (why should we break our immutable data model just to make the spec generation happy???) and to be able to specify the maximum number of items in an array (you just can’t do it with the current Swagger annotations).
For our case study project, this implementation-first approach wasn’t going to cut it. Critically, we needed a much tighter feedback loop. We couldn’t afford to lose a week before we got the first feedback from our external customers on whether our proposed data model would work for them.
The even-better days: spec-first API design
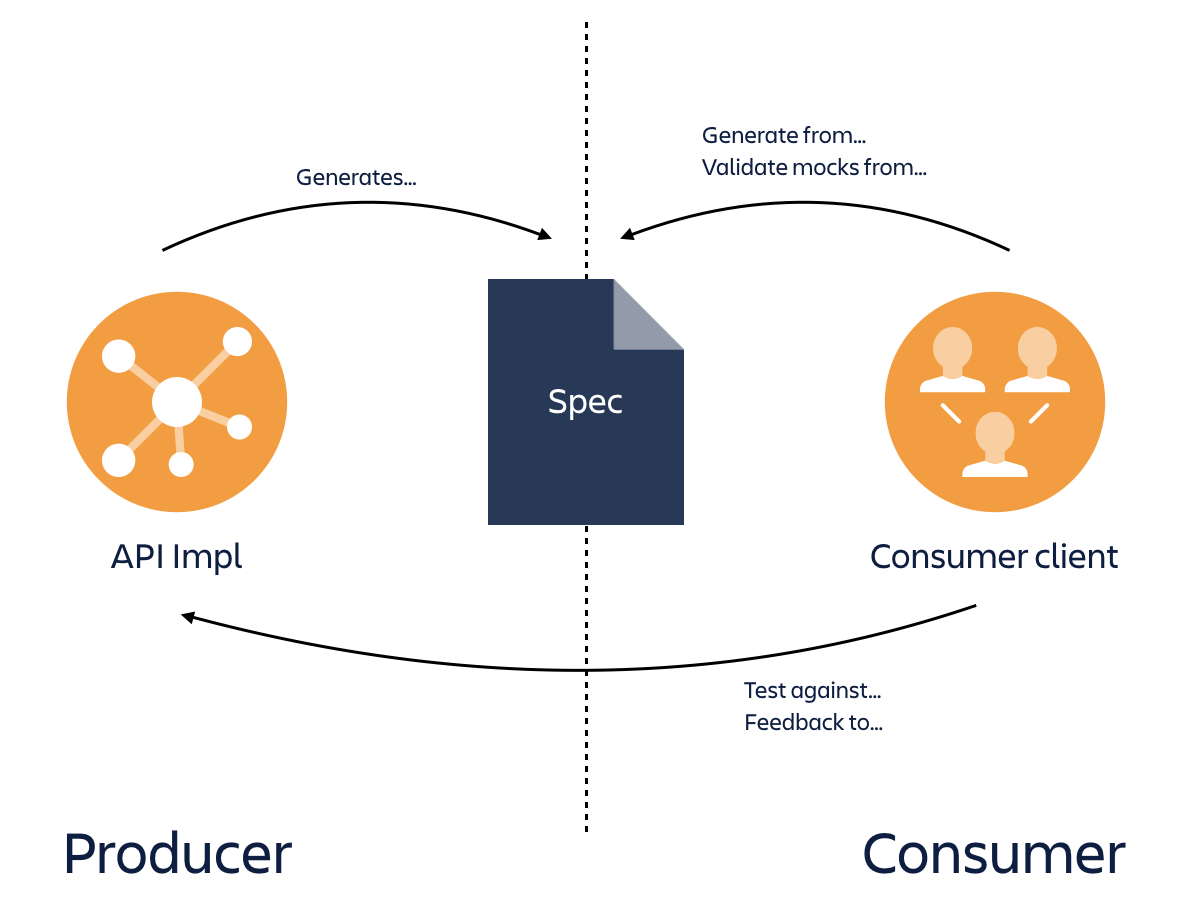
For the feature flags project, we switched to a spec-first approach, with the goal of tightening that all-important feedback loop as much as possible. Here’s what we recommend, based on what we learned:
- Design the API as a Swagger specification –This is a simple format that has an important benefit over using something like a Confluence page: it is a usable artifact. You can generate user documentation directly from it, use it in contract testing, and even use it to generate your implementation if desired.
- Get review feedback on the API design as pull requests on the Swagger spec –This has the nice property that reviewers have the entire API context at hand, and (anecdotally) I have found leads to higher-value review feedback because it is about the API design and consistency, not the implementation details.
- Encode example interactions as Pact files – As a way of showing our customers what example interactions with the API would look like, we added example Pact files that show what such interactions would look like. The great thing about this is we can validate that the examples adhere to our spec using the swagger-mock-validator which ensures our examples are kept up to date as we evolve our API.
- Provide simple tooling to preview the spec –Some people are happy reading Swagger json or yaml, others prefer a GUI. We provided super-simple tooling to allow our customers to preview the spec in swagger-ui if desired.
- Use the spec to validate your implementation – swagger-request-validator or swagger-mock-validator are great tools to validate that your implementation matches the spec.
We found this approach to be very successful. We got meaningful feedback from the team and our external customers, and were able to iterate on the API design really quickly.

It also meant that our integrators could begin implementation on their side without needing to wait for us to finish our API implementation. They could build mocks from the Swagger spec and use that to drive tests of their implementation with confidence that it would match our implementation. We got some really positive feedback from our external partners on this approach!
Benefits of spec-first design
To distill the discussion above, Fusion has found the following benefits with the spec-first approach:
- Tight feedback loops. You can get internal and/or external feedback within hours, not days.
- Effective feedback. The review feedback you get is about the API design, not implementation details.
- Minimal wasted effort. The Swagger spec is usable on both the Provider and Consumer side for contract validation and code generation (which a Confluence page isn’t), and you haven’t invested a lot of effort in implementation in the case where large-scale API changes are needed after review.
- Contract testing for safety. We get immediate feedback in our tests when we make a breaking change to our API implementation by validating against our API spec.
Full disclosure: there are some rough edges
I’m not going to pretend everything with this approach is sunshine and rainbows. We’ve found it to be a great way to build APIs, but there have been a few kinks. We’re working on ironing them out and iterating on the overall process.
- Giving examples of bad requests – The swagger-mock-validator does a great job of validating the Pact example requests, but at the moment you can’t tell it to ignore request validation in the cases where you want to demonstrate a bad request and the expected response. It’s on our backlog, though – coming soon!
- Detecting breaking changes to the API spec – We currently don’t do any diffing on our Swagger specs to detect breaking changes. This is less important during the initial design phase, but once you hit v1.0 it becomes very important not to inadvertently introduce breaks. This is actually less of a problem in spec-first design as you can more easily pick up accidental breakages, but it’s always nice to have tools to detect this for you. The contract-testing-cli has functionality for doing this sort of detection – we just haven’t integrated it into our process yet.
- Merging APIs – This one is fairly specific to our team, but our APIs are a small part of the broader Jira Software REST API and we needed to come up with a nice way to merge multiple Swagger specs into a single document that we then use to generate our user documentation from. There is some tooling available for this which is becoming more mature.
Speaking of tooling…
To pull off this approach, and ensure we can do it safely, we leverage some awesome tooling developed within Atlassian and the wider OSS community.
swagger
Swagger is an API specification format and supporting tooling. It has become the de-facto standard for REST API specification in the form of the OpenAPI initiative (of which Atlassian is a member). It is also the standard format for REST API specifications in Atlassian.
swagger-ui
https://swagger.io/tools/swagger-ui/
A super simple way to preview your Swagger / OpenAPI specifications in a pretty GUI during development. Its also a great way for your customers to explore your API if they don’t like staring at JSON or YAML.
(We actually use swagger-ui-express to spin up swagger-ui for our specs)
Pact
Pact is a consumer-driven contract testing tool used extensively at Atlassian. It defines a schema for ‘pacts’ which are request/response interactions against an API.
We use this format to provide example API interactions. The beauty of using Pact for this (rather than a README or Confluence page etc.) is that the example interactions can be validated against the API spec using the swagger-mock-validator. This means our examples are always up-to-date with the API as we evolve it.
swagger-request-validator
https://bitbucket.org/atlassian/swagger-request-validator
The swagger-request-validator is a Java library for validating request/response interactions against a Swagger / OpenAPI specification. We use it in our REST Assured tests to validate that our implementation matches our specification. This gives us the confidence that we can let our customers work from our API specification at the same time as we build out our implementation. On the other side of the fence, consumers can use the WireMock module to ensure that the mocks they use to drive their tests also adheres to the spec.
swagger-mock-validator
https://bitbucket.org/atlassian/swagger-mock-validator
For non-Java projects, the swagger-mock-validator fills the same role as the swagger-request-validator. It is used to validate that Pact files adhere to an API spec, and can be used on both the producer and consumer side. We use it to validate that our example interactions validate against our API specification, and that our API specification matches our proposed request/response interactions.
swagger-codegen
https://swagger.io/tools/swagger-codegen/
Swagger Codegen let you generate server stubs and clients for APIs based on a Swagger / OpenAPI specification. Our customers can use this to generate clients that will be able to interact with our API, and they can use it to generate mock servers to develop against while the wait for our implementation to be complete.
If you could nerd out on technical details like this all day, you might be a great fit for our engineering team. We’re hiring. Lots.